基本信息 如果要看具体的功能点说明的话,请直接跳到功能点章节。
ClickHouse数据库中收集到的日志导出为csv后已放在box上,下载地址如下。
https://box.nju.edu.cn/f/f1b6dd967896407da751/
最后可以在对应的Flink环境上运行的jar包的地址如下。
https://box.nju.edu.cn/f/fbf09bfa6f63446fb2f9/
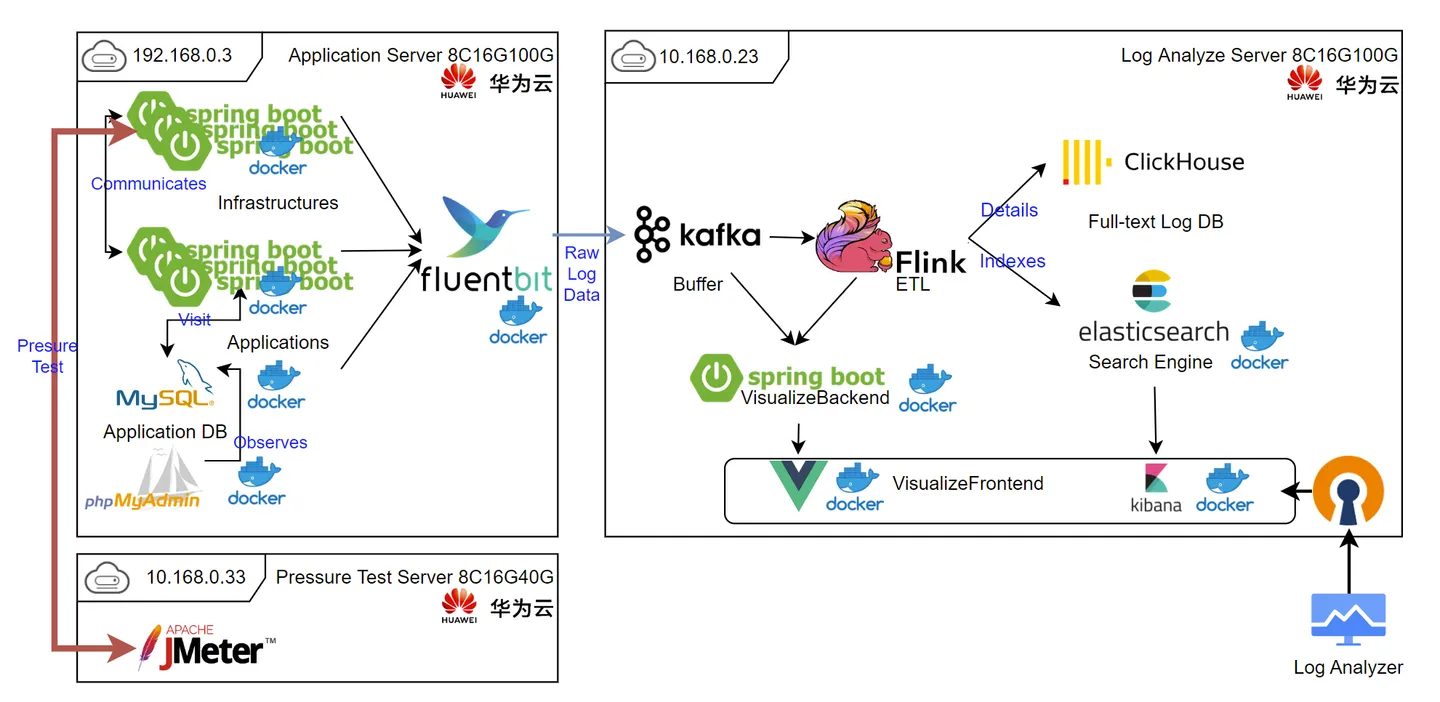
环境搭建 承载平台 本次使用的计算平台均位于华为云上。整体架构图如下所示。
本地管理员所有对远端的交互均透过特定工具在内网进行。华为云服务器间内网速度默认为1Gbps,本地到华为云服务器的公网IP均为按量付费的100M宽带。应用服务器IP后期为 10.168.0.3。
上图左侧的SpringBoot容器数量仅供示意。请以下面的docker ps -a为准。
微服务服务器 8C16G的华为云HECS。使用六一八特惠购买1年,全程保持开机。
该服务器的内网IP地址为 192.168.0.3。
后期改用临时按量付费的ECS,配置也为8核16G,IP地址 10.168.0.3。运行环境细节不变。
日志分析服务器 该服务器为按量付费模式,每次使用后进入关机不计费模式,以节省云资源费用。
具体到性能方面,可以动态使用4C16G以上的规格保证各个组件能够顺利运行。
该服务器的内网IP地址为10.168.0.23。
CICD服务器 该服务器由于和本次作业相关性不高,在上面的图中并未画出。
所有对业务逻辑和数据库服务器的访问均通过特定工具进行,华为云服务器不映射内容到公网。
后期改成在日志分析服务器上起特定工具供用户使用。阿里云小水管效率有点低。
文档与代码管理 所有代码和文档都托管到南大Git上。前后端API管理使用Apifox。所有的大文件通过华为云OBS传输。做好的视频(如果有)会放在南大Git上。
环境一览 软件版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 . ├── flink-1.13.6-bin-scala_2.11.tgz ├── kafka_2.11-2.1.1.tgz ├── scala-2.11.12.rpm ├── jdk-8u321-linux-x64.tar.gz ├── apache-maven-3.8.7-bin.tar.gz └── apache-jmeter-5.5.zip clickhouse-server: 22.3.3.44 (official build) clickhouse-client: 22.3.3.44 (official build) fluent/fluent-bit:1.6-debug docker.elastic.co/elasticsearch/elasticsearch:7.8.1 docker.elastic.co/kibana/kibana:7.8.1 docker.elastic.co/elasticsearch/elasticsearch:6.8.13 docker.elastic.co/kibana/kibana:6.8.13 mysql:8.0 dushixiang/kafka-map:latest phpmyadmin/phpmyadmin:latest
端口占用 由于这些应用有时候会随机选择一些高位端口,下面只列出相对固定的端口。
类别
用途
端口
对应服务器
是否可以网页查看
是否为默认端口
SSH
SSH
22微服务、日志分析
否 是
MySQL
数据库
3306微服务
否 是
phpmyadmin
数据库面板
8080微服务
是
否
fluentbit
收集本地日志
24224微服务
否 是
elasticsearch
收集日志数据
9200日志分析
是
是
kibana
网页界面
5601日志分析
是
是
Flink
网页面板
8088日志分析
是
是
Kafka
broker
9092日志分析
否
是
zookeeper
2181否
是
ClickHouse
http_port
8123日志分析
是
是
tcp_port
9001否 否
mysql_port
9004否 是
postgresql_port
9005否 是
Kafka-Map
WebUI
8080日志分析
是
是
环境变量 /etc/profile1 2 3 4 5 6 7 FLINK_HOME=/usr/local/flink KAFKA_HOME=/usr/local/kafka JAVA_HOME=/usr/local/java8 PATH=$PATH :$FLINK_HOME /bin PATH=$PATH :$KAFKA_HOME /bin export PATH
配置文件 由于配置文件过多,仅和配置Java环境变量和端口相关的此处从略,仅列出重要项。这里不包括在docker-compose中指定的内容。
fluent-bitfluent-bit.conf1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [SERVICE] flush 1 log_Level info daemon off http_server on http_listen 0.0.0.0 http_port 2020 storage.metrics on Parsers_File parsers.conf [INPUT] name forward max_chunk_size 1M max_buffer_size 5M [FILTER] Name parser Match * Key_Name log Parser docker Preserve_Key True Reserve_Data True [OUTPUT] name kafka match * brokers 10.168.0.23:9092 topics mx
parsers.conf1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 [PARSER] Name apache Format regex Regex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name apache2 Format regex Regex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^ ]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>.*)")?$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name apache_error Format regex Regex ^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\](?: \[pid (?<pid>[^\]]*)\])?( \[client (?<client>[^\]]*)\])? (?<message>.*)$ [PARSER] Name nginx Format regex Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)") Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name k8s-nginx-ingress Format regex Regex ^(?<host>[^ ]*) - (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)" (?<request_length>[^ ]*) (?<request_time>[^ ]*) \[(?<proxy_upstream_name>[^ ]*)\] (\[(?<proxy_alternative_upstream_name>[^ ]*)\] )?(?<upstream_addr>[^ ]*) (?<upstream_response_length>[^ ]*) (?<upstream_response_time>[^ ]*) (?<upstream_status>[^ ]*) (?<reg_id>[^ ]*).*$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name json Format json Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On [PARSER] Name docker-daemon Format regex Regex time="(?<time>[^ ]*)" level=(?<level>[^ ]*) msg="(?<msg>[^ ].*)" Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On [PARSER] Name syslog-rfc5424 Format regex Regex ^\<(?<pri>[0-9]{1,5})\>1 (?<time>[^ ]+) (?<host>[^ ]+) (?<ident>[^ ]+) (?<pid>[-0-9]+) (?<msgid>[^ ]+) (?<extradata>(\[(.*?)\]|-)) (?<message>.+)$ Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L%z Time_Keep On [PARSER] Name syslog-rfc3164-local Format regex Regex ^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$ Time_Key time Time_Format %b %d %H:%M:%S Time_Keep On [PARSER] Name syslog-rfc3164 Format regex Regex /^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$/ Time_Key time Time_Format %b %d %H:%M:%S Time_Keep On [PARSER] Name mongodb Format regex Regex ^(?<time>[^ ]*)\s+(?<severity>\w)\s+(?<component>[^ ]+)\s+\[(?<context>[^\]]+)]\s+(?<message>.*?) *(?<ms>(\d+))?(:?ms)?$ Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On Time_Key time [PARSER] Name envoy Format regex Regex ^\[(?<start_time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)? (?<protocol>\S+)" (?<code>[^ ]*) (?<response_flags>[^ ]*) (?<bytes_received>[^ ]*) (?<bytes_sent>[^ ]*) (?<duration>[^ ]*) (?<x_envoy_upstream_service_time>[^ ]*) "(?<x_forwarded_for>[^ ]*)" "(?<user_agent>[^\"]*)" "(?<request_id>[^\"]*)" "(?<authority>[^ ]*)" "(?<upstream_host>[^ ]*)" Time_Format %Y-%m-%dT%H:%M:%S.%L%z Time_Keep On Time_Key start_time [PARSER] Name cri Format regex Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$ Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L%z [PARSER] Name kube-custom Format regex Regex (?<tag>[^.]+)?\.?(?<pod_name>[a-z0-9](?:[-a-z0-9]*[a-z0-9])?(?:\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-(?<docker_id>[a-z0-9]{64})\.log$
Kafka除了安装过程中的调整,无需要注意的配置文件。
搭建过程 虚拟化、系统安装和SSH配置 华为云买来就有,略。系统均为CentOS 7.9 64位,x86_64架构。
Docker的安装也是完全按照官网进行的,这里忽略不计。
https://docs.docker.com/engine/install/centos/
为了让内部容器可以访问外部网络,为系统参数加上了 net.ipv4.ip_forward=1。
配置环境变量 如前文所述。修改完后要执行如下命令。
Java搭建解压,配置JAVA_HOME,没什么好说的。
Maven搭建实测使用CentOS 7源自带的3.0.5会出现如下错误。
1 SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder" .
故需要手动安装Maven。我们选择的是Maven 3.8.7。安装过程按如下链接进行。
https://linuxize.com/post/how-to-install-apache-maven-on-centos-7/
该链接中用的maven版本和我们用的不同,但其他步骤是一样的。
Scala搭建直接装官网下载的rpm包。rpm装完即可。
确实没什么值得说的。
Flink搭建完全按照如下链接进行。
https://www.jianshu.com/p/bbaa8d72cfcf
把文件下载下来,解压,配置环境变量(前文已提及)、修改配置,即可开箱即用。
实际上,并不完全是开箱即用。我补充了相当大量的依赖到 $FLINK_HOME/lib 中。实际可用的该目录内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 elasticsearch-7.8.1.jar flink-sql-connector-elasticsearch7_2.11-1.13.6.jar elasticsearch-rest-client-7.8.1.jar flink-table_2.11-1.13.6.jar elasticsearch-rest-high-level-client-7.8.1.jar flink-table-blink_2.11-1.13.6.jar elasticsearch-x-content-7.8.1.jar flink-connector-elasticsearch7_2.11-1.13.6.jar log4j-1.2-api-2.17.1.jar flink-csv-1.13.6.jar log4j-api-2.17.1.jar flink-dist_2.11-1.13.6.jar log4j-core-2.17.1.jar flink-json-1.13.6.jar log4j-slf4j-impl-2.17.1.jar flink-shaded-zookeeper-3.4.14.jar
以上带有elasticsearch的jar包都是由于官方的Flink 1.13.6 connector支持的elasticsearch版本太低,因此打出的包缺乏对接新elasticsearch的能力。
之所以不把这些依赖打到本地,是因为打包在jar包里的话每次上传下载的网络成本太高。实际操作的时候,YDJSIR是真的看一次报错就去搜哪个类找不到,缺了哪个依赖,就去 mvnrepository一个个补齐。而这一切的的出发点,来自于这篇StackOverflow。
https://stackoverflow.com/questions/70576213/flink-table-api-sink-es-on-server-has-error-java-lang-noclassdeffounderror-coul
NoClassDefFoundError indicate that there may be a conflict in the es version, you can try to use the flink-sql-connector-elasticsearch jar package directly.
YDJSIR正是从前半句获得启发,并成功找到了很多类 NoClassDefFoundError 的问题。
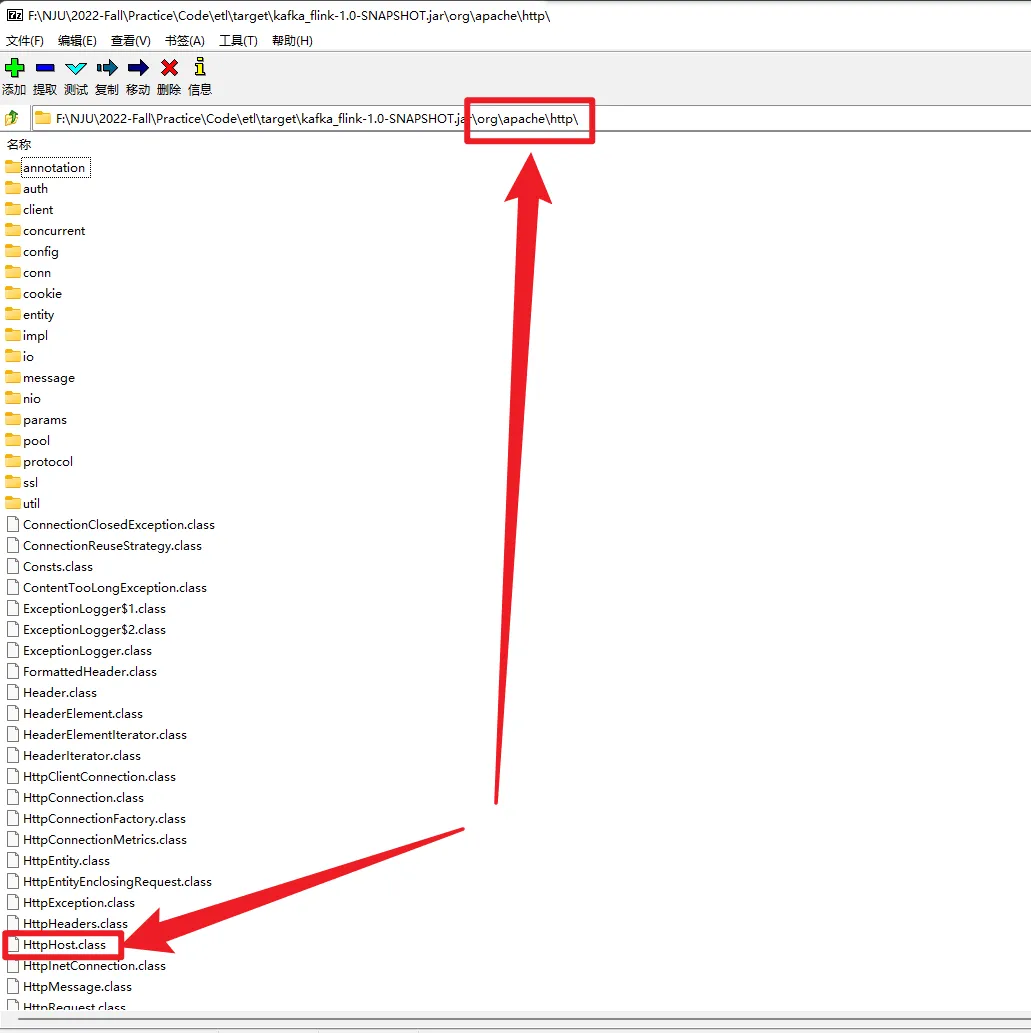
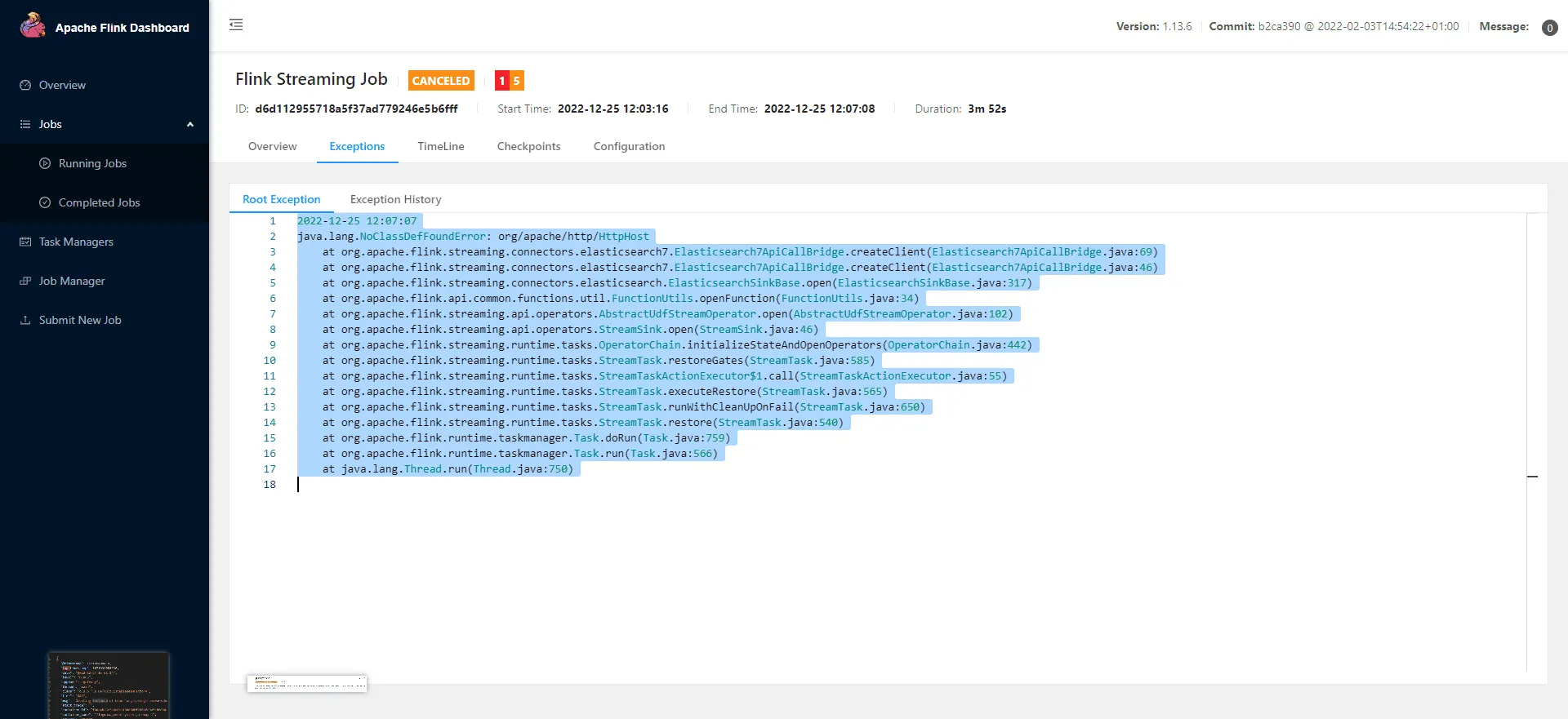
后面又莫名其妙地遇到了找不到HttpHost这个类的错,最后不得不暂时放弃在线运行方案,先主动降低elasticsearch和Kibana版本到6.8.13。
而后问题迎刃而解。
Kafka搭建完全按照如下链接进行。
https://www.cnblogs.com/qpf1/p/9161742.html
参考如下链接修改了配置。
https://blog.csdn.net/qq_37140416/article/details/106824442?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2.pc_relevant_aa&utm_relevant_index=4
都改为10.168.0.23的IP。且ZooKeeper监听的端口默认2181。
Kafka没有设置开机自启,而是按需启动启动过程如下。
1 2 3 nohup $KAFKA_HOME /bin/zookeeper-server-start.sh $KAFKA_HOME /config/zookeeper.properties > zookeeper-run.log 2>&1 & nohup $KAFKA_HOME /bin/kafka-server-start.sh $KAFKA_HOME /config/server.properties > kafka-run.log 2>&1 & $KAFKA_HOME /bin/kafka-topics.sh --create --zookeeper 10.168.0.23:2181 --replication-factor 1 --partitions 1 --topic mx
实际使用时,Kafka仅在需要的时候开启。具体可查看视频。
为了DEBUG,使用基于命令行的生产者和消费者进行测试。后期由于引入了Kafka-map,可以使用网页直接进行观察,但仍然将命令记录在这里。
1 2 $KAFKA_HOME /bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mx $KAFKA_HOME /bin/kafka-console-consumer.sh --bootstrap-server 10.168.0.23:9092 --topic mx --from-beginning
Kafka-Map搭建我们使用Kafka-Map进行Kafka运行状态的可视化。
由于该应用使用Docker部署,没什么值得特别留意的内容。直接启动即可。
JMeter 搭建本来考虑的是在本地Windows写好,而后放到华为云内网的一个按量付费ECS里面,然后用纯命令行跑。然后本地和线上的访问地址是不完全一样的,所以很麻烦。后来找到了这样的一个方案。
https://stackoverflow.com/questions/67419731/use-jmeter-desktop-application-as-web-app
正当我们打算摩拳擦掌执行的时候,突然发现利用MobaXterm这种自带X11转发的SSH终端连接服务器时,JMeter的GUI本身就会直接显示在本地的电脑上。这下折腾了个寂寞。
ClickHouse搭建完全按照官网文档进行。使用yum安装ClickHouse。具体指令如下。
1 2 3 sudo yum install -y yum-utilssudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.reposudo yum install -y clickhouse-server clickhouse-client
装完后很显然不能缺少的步骤是要放开远端访问。
https://blog.csdn.net/zhangpeterx/article/details/95059059
fluentbit搭建1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 version: '3.7' services: fluent-bit: image: fluent/fluent-bit:1.6 container_name: flb01 volumes: - ./conf:/fluent-bit/etc ports: - 24224 :24224 - 5140 :5140/udp - 2020 :2020 logging: driver: "json-file" options: max-size: 100m max-file: "5" networks: - elastic ubuntu: image: ubuntu command: [/bin/echo , "Dotnet Plus!" ] depends_on: - fluent-bit networks: - elastic logging: driver: fluentd options: fluentd-address: localhost:24224 tag: docker-ubuntu networks: elastic: driver: bridge
elasticsearch和Kibana搭建注意,在运行下面的docker-compose之前,需要按照下面的链接修改系统参数。
https://stackoverflow.com/questions/51445846/elasticsearch-max-virtual-memory-areas-vm-max-map-count-65530-is-too-low-inc
1 >sysctl -w vm.max_map_count=262144
is correct, however, the setting will only last for the duration of the session. If the host reboots, the setting will be reset to the original value.
If you want to set this permanently, you need to edit /etc/sysctl.conf and set vm.max_map_count to 262144.
When the host reboots, you can verify that the setting is still correct by running sysctl vm.max_map_count
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 version: '3.7' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.8.1 container_name: es01 volumes: - type: bind source: ./es target: /usr/share/elasticsearch/data ports: - "9200:9200" networks: - elastic environment: - node.name=es01 - cluster.name=es-docker-cluster - bootstrap.memory_lock=false - cluster.initial_master_nodes=es01 - "ES_JAVA_OPTS=-Xms2048m -Xmx2048m" kibana: image: docker.elastic.co/kibana/kibana:7.8.1 container_name: kib01 links: - "elasticsearch" ports: - 5601 :5601 environment: ELASTICSEARCH_URL: http://es01:9200 ELASTICSEARCH_HOSTS: http://es01:9200 networks: - elastic networks: elastic: driver: bridge
此后,为了减少兼容性问题,将 Kibana 和 elasticsearch 的版本降低到了6.8.13 ,修改后的yml如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 version: '3' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:6.8.13 container_name: es01 environment: - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms2048m -Xmx2048m" ulimits: memlock: soft: -1 hard: -1 ports: - "9200:9200" kibana: image: docker.elastic.co/kibana/kibana:6.8.13 container_name: kib01 links: - "elasticsearch" ports: - "5601:5601"
设置服务开机自启 对于Docker部署的,使用docker update将其设置加上--restart=unless-stopped。
设置ClickHouse服务自启。
1 systemctl enable clickhouse-server
Kafka和Flink没有设置开机自启。
日志数据生产 微服务代码说明 我们开发了三个微服务(user-service:用户服务;comment-service:评论服务;like-service:点赞服务),一个网关和两个服务发现服务(同一份代码,两份配置文件)。
这几个服务使用的都是标准的Spring Cloud框架,具体的业务流程可以理解为,用户注册后登录,而后可以发布评论。发布评论后,他自己或者是其他的用户可以对改该评论点赞。点赞后再次发送点赞请求的结果是取消点赞。
服务之间存在相互调用。例如,调用点赞接口时,点赞服务会需要调用评论服务以获取评论相关信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Component @Slf4j public class LikeService { @Autowired CommentLikesDao commentLikesDao; @Autowired CommentRestTemplateClient commentRestTemplateClient; public ResultVo likeComment (CommentLikesKey commentLikesKey) { CommentVo comment = commentRestTemplateClient.getComment(commentLikesKey.getCommentId()); if (comment == null ) { log.error("User ID: {} tries to like an not-existent comment ID: {}" , TokenThreadLocalUtil.get().getUserId(), commentLikesKey.getCommentId()); return new ResultVo (StatusCode.FAIL, "You are trying to like a not-existent comment!" ); } if (commentLikesDao.selectByPrimaryKey(commentLikesKey.getCommentId(), commentLikesKey.getUserId()) != null ) { if (commentLikesDao.deleteByPrimaryKey(commentLikesKey) > 0 ) { log.info("User ID: {} cancels like on comment: {}" , commentLikesKey.getUserId(), commentLikesKey.getCommentId()); return new ResultVo (StatusCode.SUCCESS, "You cancelled like on comment " + commentLikesKey.getCommentId()); } } else { if (commentLikesDao.insert(commentLikesKey) > 0 ) { log.info("User ID: {} likes comment: {}" , commentLikesKey.getUserId(), commentLikesKey.getCommentId()); return new ResultVo (StatusCode.SUCCESS, "You likes comment " + commentLikesKey.getCommentId()); } } return new ResultVo (StatusCode.FAIL, "Failure" ); } }
其中common仓库用于放置所有项目共用的一些类,会通过maven以来的方式在打包时注入其他项目中。
项目部署使用Jenkins作为CICD工具,用的Jenkinsfile如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 pipeline { agent { label 'ABN-HW' } stages { stage('SCM from Mirror' ) { steps { sh "ls -al" sh "pwd" } } stage('Build' ) { steps { sh "bash start.sh" } } stage('Start' ) { steps { sh 'docker-compose -p lms down | true' sh 'docker-compose -p lms up -d --force-recreate --scale userservice=2 --scale commentservice=2 --scale likeservice=2' } } } }
其中调用的 start.sh 内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 export JAVA_HOME=/usr/local/java8/cd commonmvn install cd ../comment-servicemvn clean package docker:build cd ../like-servicemvn clean package docker:build cd ../user-servicemvn clean package docker:build cd ../gatewaymvn clean package docker:build cd ../eurekaservermvn clean package docker:build
手动运行后的结果如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 root@hecs-275762:~/logmanagementsystem# docker-compose -p lms up -d --force-recreate --scale userservice=2 --scale commentservice=2 --scale likeservice=2 Recreating lms_gateway_1 ... done Recreating lms_commentservice_1 ... done Recreating lms_commentservice_2 ... done Recreating eureka-server1 ... done Recreating lms_likeservice_1 ... done Recreating lms_likeservice_2 ... done Recreating eureka-server2 ... done Recreating lms_userservice_1 ... done Recreating lms_userservice_2 ... done root@hecs-275762:~/logmanagementsystem# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES af22808e7bd4 userservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49191->8888/tcp, :::49191->8888/tcp lms_userservice_1 9f9a1e8d7fa0 eurekaserver:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:8762->8762/tcp, :::8762->8762/tcp eureka-server2 ebe234f632ab userservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49190->8888/tcp, :::49190->8888/tcp lms_userservice_2 4e7b47a83e87 likeservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49188->8890/tcp, :::49188->8890/tcp lms_likeservice_1 bc1ffc707537 eurekaserver:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:8761->8761/tcp, :::8761->8761/tcp eureka-server1 c4e399513f69 likeservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49189->8890/tcp, :::49189->8890/tcp lms_likeservice_2 ae73ba8c004a gateway:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:8000->8000/tcp, :::8000->8000/tcp lms_gateway_1 173ad2ba51a8 commentservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49187->8889/tcp, :::49187->8889/tcp lms_commentservice_2 4bb3b370c6eb commentservice:logMS "/bin/sh -c ./run.sh" 3 minutes ago Up 3 minutes 0.0.0.0:49186->8889/tcp, :::49186->8889/tcp lms_commentservice_1 84d981a740fe fluent/fluent-bit:1.6 "/fluent-bit/bin/flu…" 11 days ago Up 13 hours 0.0.0.0:2020->2020/tcp, :::2020->2020/tcp, 0.0.0.0:24224->24224/tcp, :::24224->24224/tcp, 0.0.0.0:5140->5140/udp, :::5140->5140/udp flb01 b01c77fd5ab5 phpmyadmin "/docker-entrypoint.…" 2 weeks ago Up 20 hours 0.0.0.0:8080->80/tcp, :::8080->80/tcp phpmyadmin caa52aae33c5 mysql:5.6 "docker-entrypoint.s…" 3 weeks ago Up 20 hours 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp mysql
下面是服务关闭时的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@hecs-275762:~/logmanagementsystem# docker-compose -p lms down Stopping lms_userservice_1 ... done Stopping eureka-server2 ... done Stopping lms_userservice_2 ... done Stopping lms_likeservice_1 ... done Stopping eureka-server1 ... done Stopping lms_likeservice_2 ... done Stopping lms_gateway_1 ... done Stopping lms_commentservice_2 ... done Stopping lms_commentservice_1 ... done Removing lms_userservice_1 ... done Removing eureka-server2 ... done Removing lms_userservice_2 ... done Removing lms_likeservice_1 ... done Removing eureka-server1 ... done Removing lms_likeservice_2 ... done Removing lms_gateway_1 ... done Removing lms_commentservice_2 ... done Removing lms_commentservice_1 ... done Removing network lms_logMS-net
这些微服务的特点是输出的日志都是json,方法是让SpringBoot自带的logback的输出格式为json。配置文件如下。(以某个服务为例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <?xml version="1.0" encoding="UTF-8" ?> <configuration scan ="true" scanPeriod ="30 seconds" packagingData ="true" > <appender name ="STDOUT" class ="ch.qos.logback.core.ConsoleAppender" > <encoder class ="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder" > <jsonGeneratorDecorator class ="net.logstash.logback.decorate.FeatureJsonGeneratorDecorator" /> <providers > <timestamp > <fieldName > log_timestamp</fieldName > <pattern > [UNIX_TIMESTAMP_AS_NUMBER]</pattern > </timestamp > <pattern > <pattern > { "date": "%date{yyyy-MM-dd HH:mm:ss}", "level": "%level", "appName" : "commentService", "thread": "%thread", "class": "%logger{40}", "line": "%line", "msg": "%msg", "stack_trace": "%exception" } </pattern > </pattern > </providers > </encoder > </appender > <root level ="debug" > <appender-ref ref ="STDOUT" /> </root > </configuration >
压测脚本说明 实际上,我们已经设置了相当多数量的日志。Eureka Server和剩下的几个服务间本身就会保持心跳,会产生大量的日志内容。为了制造更多样化的日志,我们使用了Apifox来管理我们的文档,JMeter制造流量产生更丰富的日志。和此前数据集成的经验一样,我们采用了多次清理文件,更改输出位置等方法减轻Kafka日志带来的巨量空间消耗。具体接口列表如下。
压测使用JMeter。JMeter服务器使用了Ubuntu 20.04,本地SSH终端是MobaXterm,两边都支持X11协议,所以在终端里完全可以直接起带GUI的界面进行操作,非常方便。
我们使用图形界面进行压力测试开发,而后使用纯命令行进行测试。
下方展示的并不是生成最终结果时压测的结果
压测脚本和测试报告一并提交。提交版本和最后实际执行的线程组个数和延迟等参数不一定完全一致(因为需要反复调试的过程)。
压测生成报告的命令如下所示。
1 jmeter -n -t IssueLogger.jmx -l test.jtl -e -o ./report
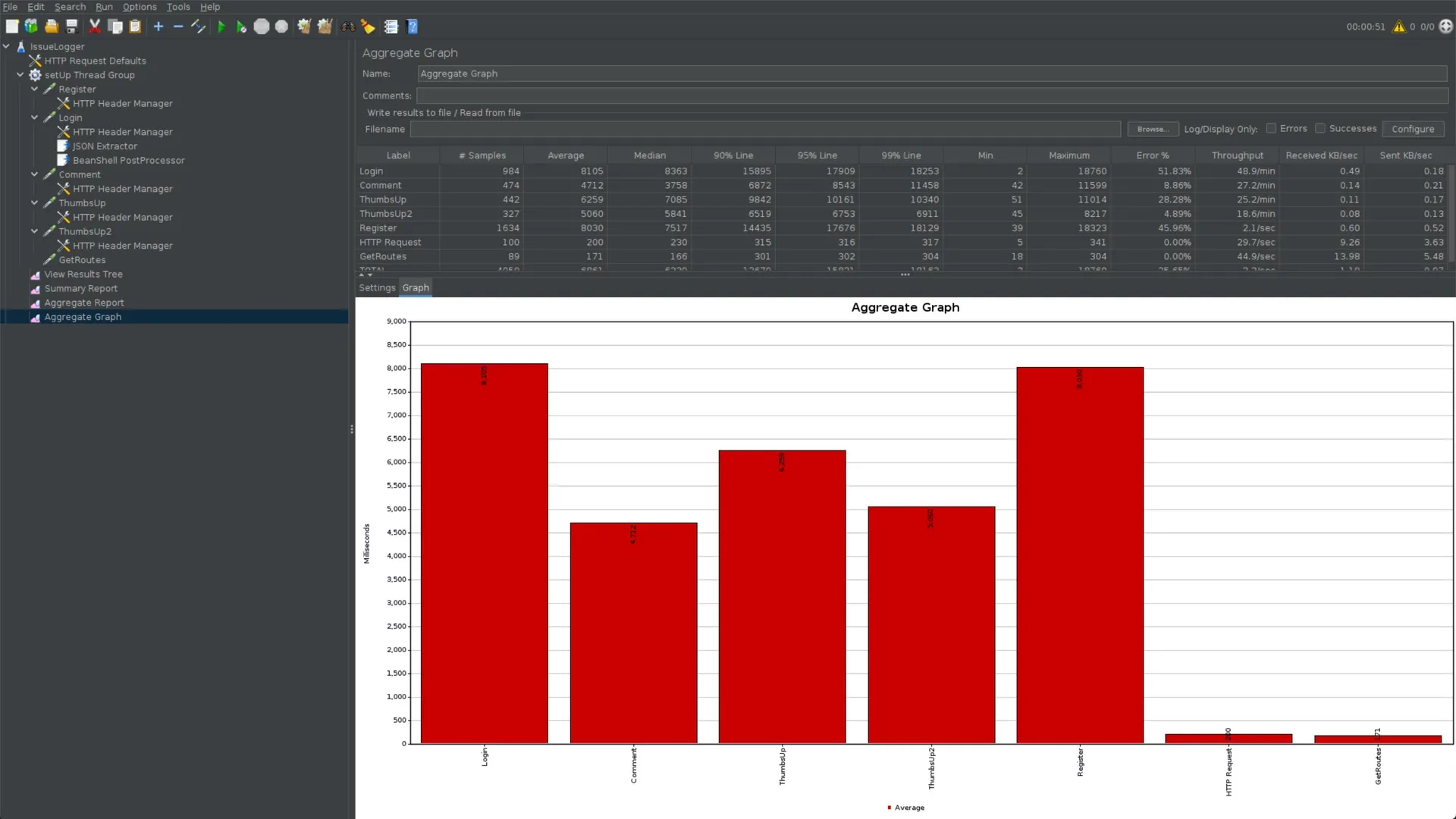
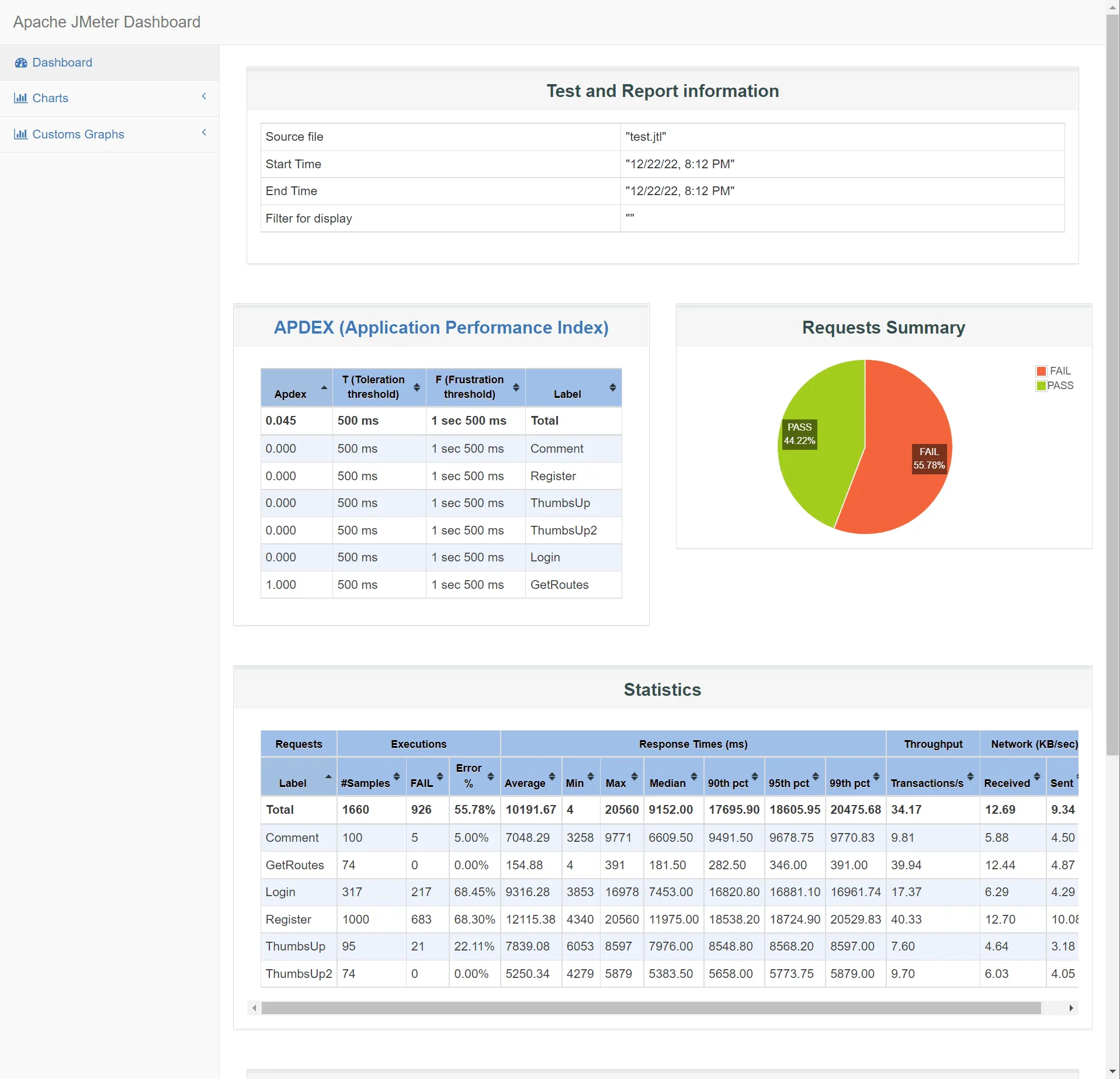
压测时可以看到明显的负载情况。
由于服务器性能有限,且没有设计合理的缓存机制,故效果较差。1000并发时的压测报告如下图所示。
不过我们的核心是日志分析,因而这里异常比较多并不是什么问题。
恢复初始设置 为了方便统计和分析,最后具体处理日志时,会使用全新的一个topic和全空的表,确保分析过程不受干扰。
清空elasticsearch 首先,清空ES本体里面的内容。
1 curl -X DELETE "10.168.0.23:9200/lms*"
而后,在Kibana中先删除对应的Index Pattern,最后重建。
清空ClickHouse 我们选择直接Truncate表或者是删除整个表而后重建表即可。
清空Kafka Kafka自身本身就有消息的自动淘汰时间,不过这个时间比较长,不太符合我们的需要。所以我们的选择是允许删除topic,跑完一轮后主动清空Kafka对应的目录/tmp/kafka-logs/,最后删除并重建topic。
ETL过程说明 流程概述 ETL的数据流如下图所示。
日志进来后首先打上UUID,方便同步与查找。接下来,日志全文输入ClickHouse,而WARN和ERROR级别的日志则会在去掉全文后插入elasticsearch。
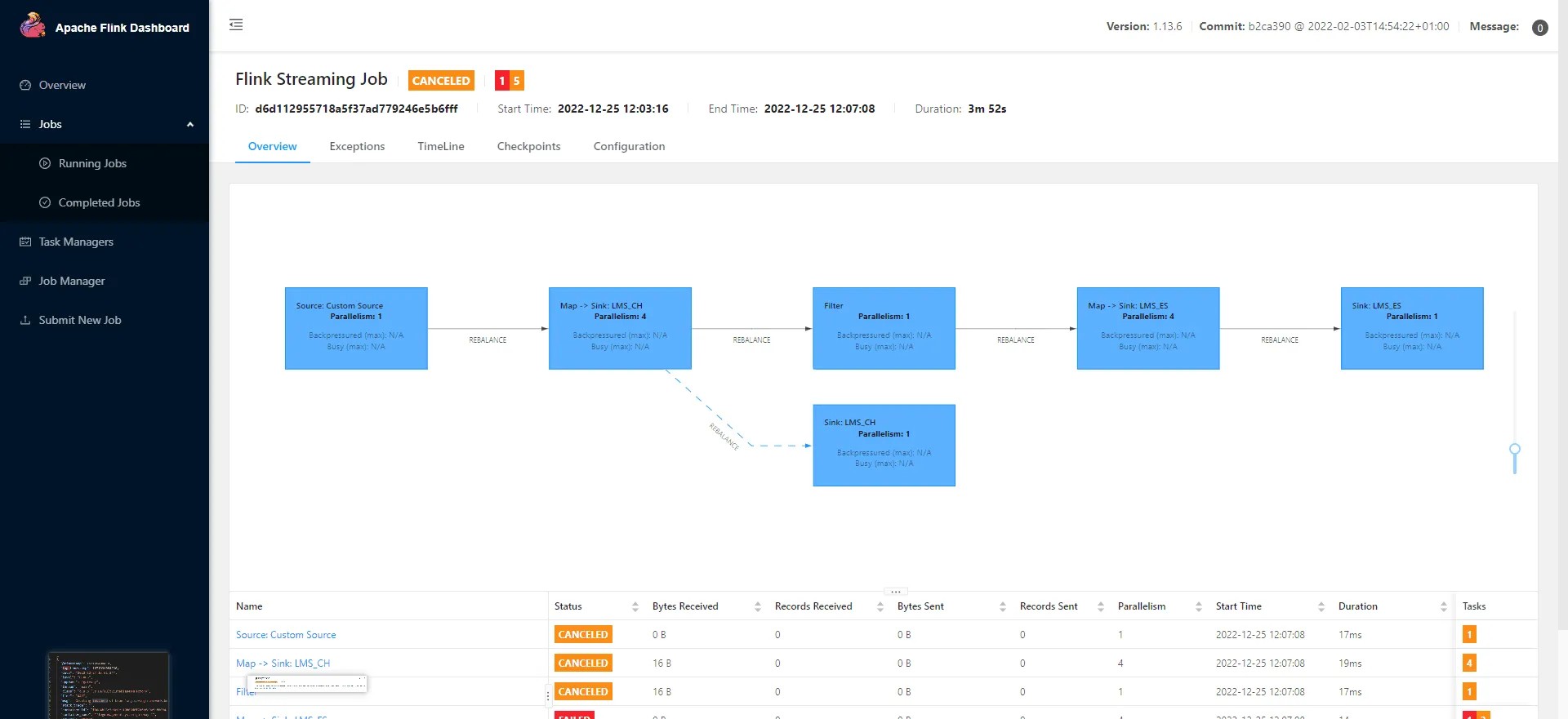
这个程序在本地可以跑,但是不知为何在集群跑报如下错误。已和助教确认过jar包内已包含对应依赖,但后面发现可能是jar包冲突。已使用maven-shaded-plugin,但并没有改善,最终不得不暂时放弃在线运行方案。
后面发现把ES换到6.8.13就完全没这些问题了。
Flink细节本地打好jar包后(mvn package),上传到服务器上,运行命令。
1 flink run -c com.FlinkSinkClickhouse kafka_flink-1.0-SNAPSHOT-shaded.jar
也可以在IDEA里面直接跑。IDEA里面跑几乎没有问题。
获取源数据 使用 FlinkKafkaConsumer 从 Kafka中获得一条条字符串形式的json作为数据源。此部分内容和数据集成课程中的原理是一样的。此处不再展开。
源数据分流 对于所有进来的消息,首先进行反序列化,以实现数据项的管理,并增加UUID打上标签做分析。
1 2 3 4 5 6 7 8 9 10 DataStream<HashMap<String, Object>> lms_tagged = source.map(new MapFunction <String, HashMap<String, Object>>() { @Override public HashMap<String, Object> map (String value) throws Exception { HashMap<String, Object> eventData = JSON.parseObject(value, HashMap.class); eventData.remove("@timestamp" ); eventData.put("uuid" , UUID.randomUUID().toString()); return eventData; } }).setParallelism(GLOBAL_PARALLELISM);
使用source.filter。此部分内容和数据集成课程中的原理是一样的。具体分流策略如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 DataStream<HashMap<String, Object>> lms_prioritized = lms_tagged.filter(new FilterFunction <HashMap<String, Object>>() { @Override public boolean filter (HashMap<String, Object> stringObjectHashMap) throws Exception { String level = (String) stringObjectHashMap.get("level" ); if (level == null ) { return false ; } if (level.equals("WARN" )) { return true ; } else return level.equals("ERROR" ); } }).setParallelism(GLOBAL_PARALLELISM);
sink处理 我们的日志的最终的sink的形式有两种,ClickHouse和 elasticsearch。
对于ClickHouse的Sink,本次的实现和此前数据集成时期本质并无太多区别,都是使用HashMap取代 POJO传递参数,使用preparedStatement批量插入,但最大的变化还是加入了更多的空值和异常处理机制。
本次最大的变化是引入了elasitcsearch的sink。为了解决依赖相关问题的血泪史已经写在上面了,此处不再赘述。具体到打包出jar的问题上,我们使用了maven-shade-plugin实现将依赖包打进mvn clean package的成品里面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 3.4.1</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <minimizeJar > false</minimizeJar > </configuration > </execution > </executions > </plugin > </plugins > </build >
承接前面的依赖解决相关问题,这里也有。
1 2 3 4 5 6 <dependency > <groupId > org.elasticsearch.client</groupId > <artifactId > elasticsearch-rest-client</artifactId > <version > 7.8.1</version > <scope > compile</scope > </dependency >
具体的建立sink的过程如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 List<HttpHost> httpHosts = new ArrayList <>(); httpHosts.add(new HttpHost (HOSTNAME, 9200 , "http" )); ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink .Builder<String>( httpHosts, new ElasticsearchSinkFunction <String>() { public IndexRequest createIndexRequest (String element) { Map<String, Object> json = JSON.parseObject(element, HashMap.class); return Requests.indexRequest() .index("lms" ) .type("lms_log" ) .source(json); } @Override public void process (String element, RuntimeContext ctx, RequestIndexer indexer) { indexer.add(createIndexRequest(element)); } } ); esSinkBuilder.setFailureHandler(new ActionRequestFailureHandler () { @Override public void onFailure (ActionRequest action, Throwable failure, int restStatusCode, RequestIndexer indexer) throws Throwable { if (ExceptionUtils.findThrowable(failure, EsRejectedExecutionException.class).isPresent()) { indexer.add(action); } else if (ExceptionUtils.findThrowable(failure, ElasticsearchParseException.class).isPresent()) { } else { throw failure; } } }); esSinkBuilder.setBulkFlushMaxActions(INSERT_BATCH_SIZE); lms_StringDataStream.addSink(esSinkBuilder.build()).name(LMS_ES).setParallelism(Constant.GLOBAL_PARALLELISM);
最后发现这段代码放在按照官方文档的elasticsearch 6.5+的环境下是没有任何问题的。不需要之前的那些奇技淫巧解决依赖问题
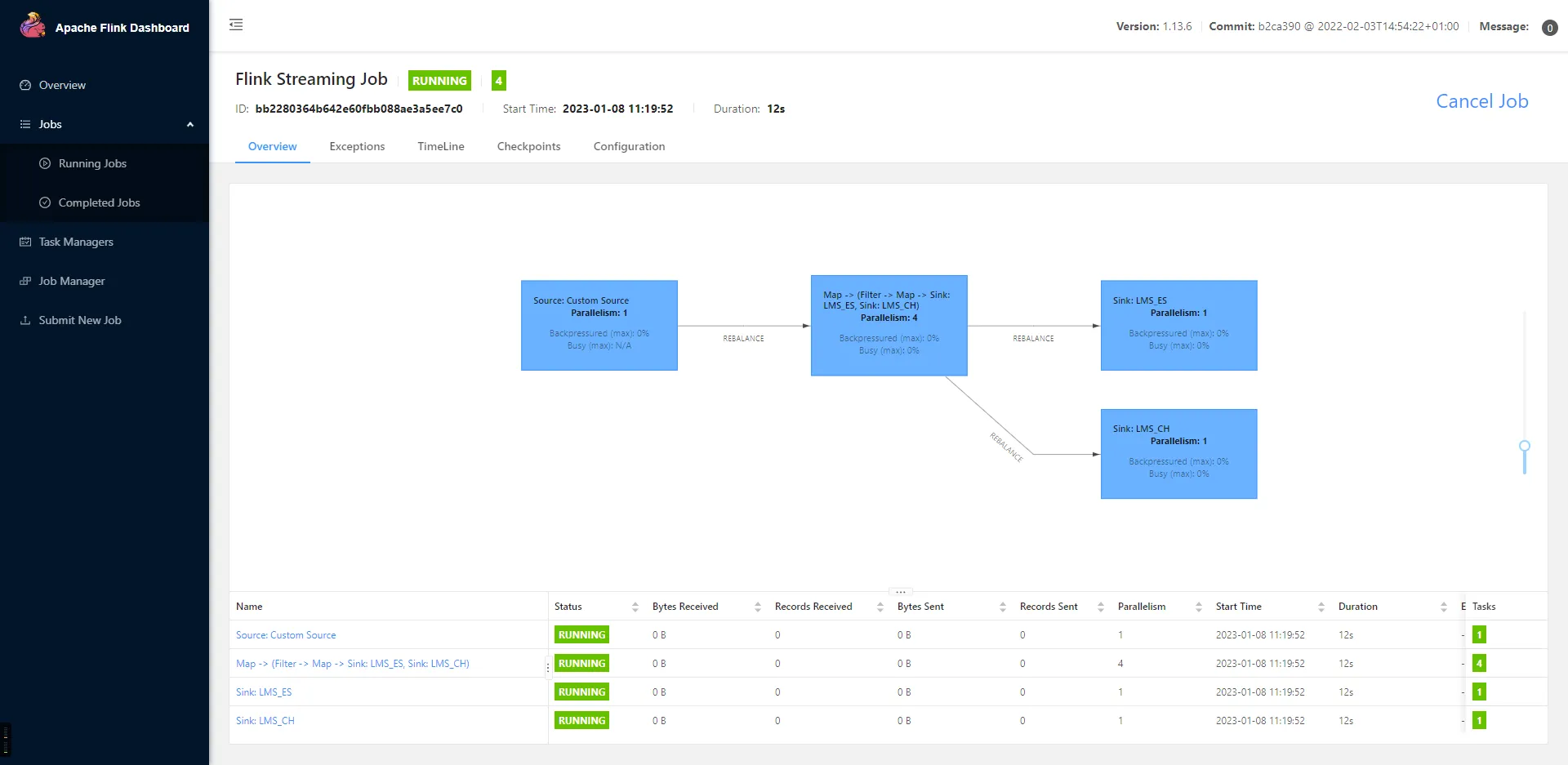
效果展示 压测时,在全部都是8核心16G的情况下,每秒记录产生约2725条日志,符合速度要求 。
此时,在ElasticSearch中我们记录了1548个异常 。
实验压测情形,此处使用的ES版本是7.8.1
我们的Flink只处理Kafka到ClickHouse的速度上限很高。毕竟是用了非常高效的log引擎实现的ClickHouse表。下图是4核16G的运行情况。读Kafka消息分区时因为是从头开始读,所以有那么100万条数据做压测。elasticsearch的速度未经测试。毕竟写入elasticsearch的日志数量很少。WARN和ERROR日志最终约1400条,下面的图是中间结果。Kafka和elasticsearch应该不是瓶颈。
在最后实际处理出最终运行的结果时,先是放置了将近四十分钟,而后开始压测,压测开始后不久中断Flink进程,完全符合作业要求。开始压测前,日志记录如下。
日志产生的过程是先放着静止状态下跑到了约15万条左右的日志,而后使用JMeter进行压测。首条和末条日志产生的时间如下。末条时间戳的序号是236800,时间戳是1673155434275。但考虑到并行度高时存在一定乱序性,实际上最大的实践戳是1673155445135。时间跨度是 10.86秒。
时间戳介于1673155434275和1673155445135,跨度10.86秒的日志有 29590条。平均每秒记录产生约2725条日志。如果按照这样的速度来看,五分钟可以产生超过80万条日志,符合速度要求。
此后我们将就这些数据开展分析。
数据库表说明 elasticsearch
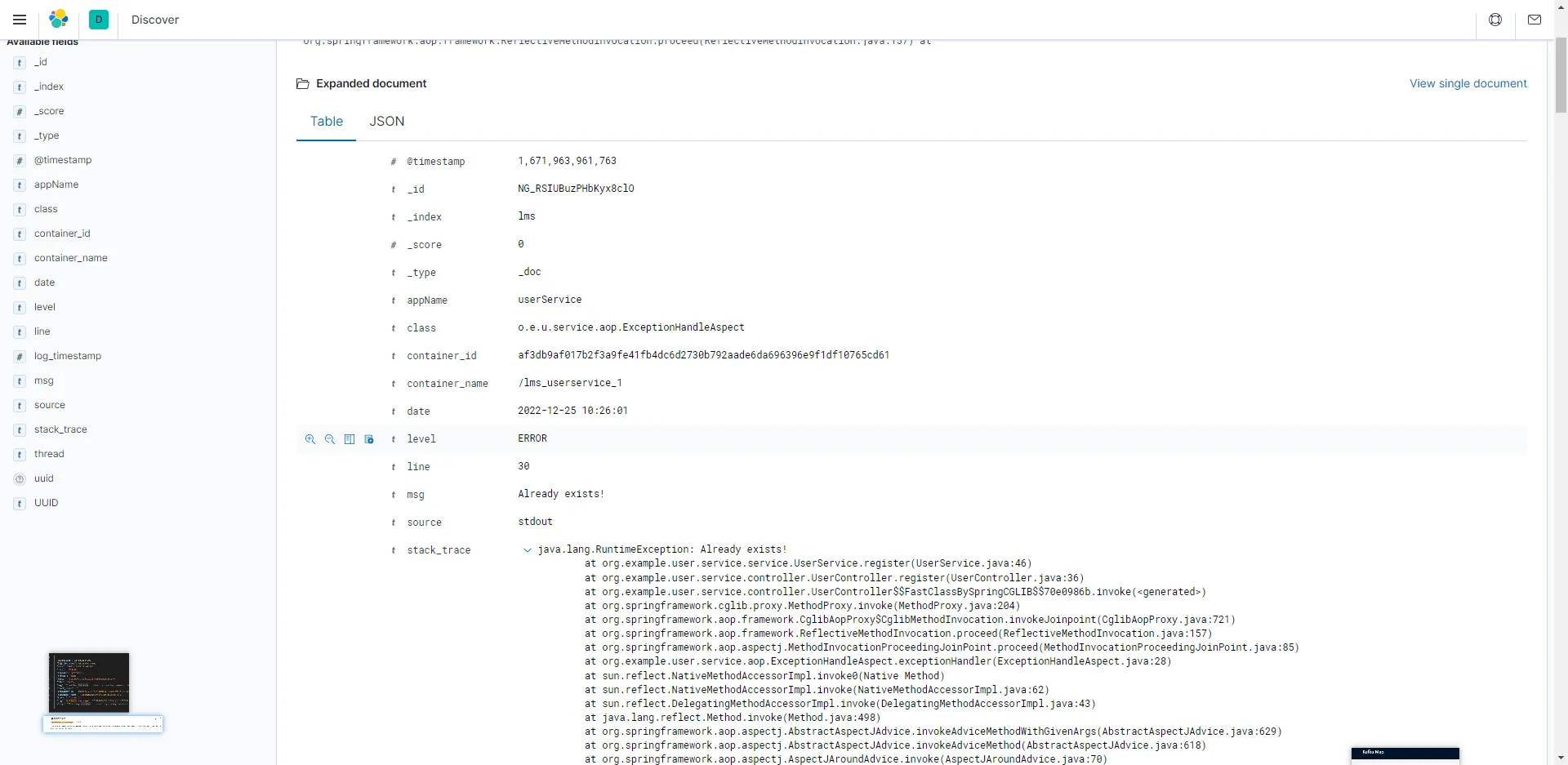
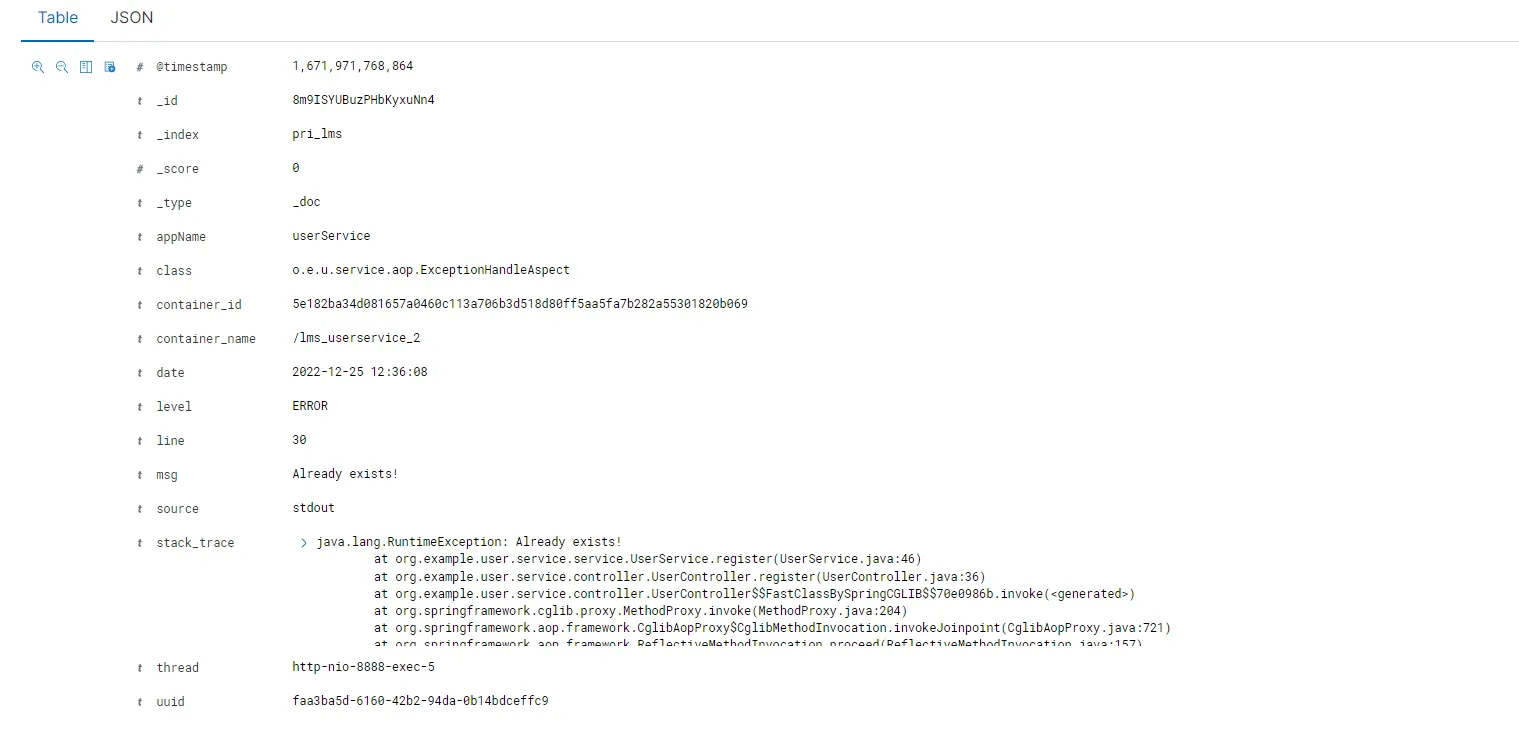
示例json如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "_index" : "pri_lms" , "_type" : "_doc" , "_id" : "8m9ISYUBuzPHbKyxuNn4" , "_version" : 1, "_score" : 0, "_source" : { "date" : "2022-12-25 12:36:08" , "msg" : "Already exists!" , "level" : "ERROR" , "appName" : "userService" , "line" : "30" , "thread" : "http-nio-8888-exec-5" , "source" : "stdout" , "uuid" : "faa3ba5d-6160-42b2-94da-0b14bdceffc9" , "@timestamp" : 1671971768864, "container_name" : "/lms_userservice_2" , "stack_trace" : "java.lang.RuntimeException: Already exists!\n\tat org.example.user.service.service.UserService.register(UserService.java:46)\n\tat org.example.user.service.controller.UserController.register(UserController.java:36)\n\tat org.example.user.service.controller.UserController$$FastClassBySpringCGLIB$$70e0986b .invoke(<generated>)\n\tat org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204)\n\tat org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation .invokeJoinpoint(CglibAopProxy.java:721)\n\tat org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)\n\tat org.springframework.aop.aspectj.MethodInvocationProceedingJoinPoint.proceed(MethodInvocationProceedingJoinPoint.java:85)\n\tat org.example.user.service.aop.ExceptionHandleAspect.exceptionHandler(ExceptionHandleAspect.java:28)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.lang.reflect.Method.invoke(Method.java:498)\n\tat org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:629)\n\tat org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:618)\n\tat org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:70)\n\tat org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)\n\tat org.springframework.aop.aspectj.MethodInvocationProceedingJoinPoint.proceed(MethodInvocationProceedingJoinPoint.java:85)\n\tat org.example.user.service.aop.RequestCostAspect.logCost(RequestCostAspect.java:25)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.lang.reflect.Method.invoke(Method.java:498)\n\tat org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:629)\n\tat org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:618)\n\tat org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:70)\n\tat org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)\n\tat org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:92)\n\tat org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)\n\tat org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor .intercept(CglibAopProxy.java:656)\n\tat org.example.user.service.controller.UserController$$EnhancerBySpringCGLIB$$58d7ddd4 .register(<generated>)\n\tat sun.reflect.GeneratedMethodAccessor54.invoke(Unknown Source)\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.lang.reflect.Method.invoke(Method.java:498)\n\tat org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205)\n\tat org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:133)\n\tat org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:116)\n\tat org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:827)\n\tat org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:738)\n\tat org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:85)\n\tat org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:963)\n\tat org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:897)\n\tat org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:970)\n\tat org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:872)\n\tat javax.servlet.http.HttpServlet.service(HttpServlet.java:648)\n\tat org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:846)\n\tat javax.servlet.http.HttpServlet.service(HttpServlet.java:729)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:230)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:192)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:99)\n\tat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:192)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.springframework.web.filter.HttpPutFormContentFilter.doFilterInternal(HttpPutFormContentFilter.java:105)\n\tat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:192)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.springframework.web.filter.HiddenHttpMethodFilter.doFilterInternal(HiddenHttpMethodFilter.java:81)\n\tat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:192)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:197)\n\tat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)\n\tat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:192)\n\tat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:165)\n\tat org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:198)\n\tat org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96)\n\tat org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:474)\n\tat org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140)\n\tat org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:79)\n\tat org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87)\n\tat org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:349)\n\tat org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:783)\n\tat org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)\n\tat org.apache.coyote.AbstractProtocol$ConnectionHandler .process(AbstractProtocol.java:798)\n\tat org.apache.tomcat.util.net.NioEndpoint$SocketProcessor .doRun(NioEndpoint.java:1434)\n\tat org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)\n\tat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\n\tat java.util.concurrent.ThreadPoolExecutor$Worker .run(ThreadPoolExecutor.java:624)\n\tat org.apache.tomcat.util.threads.TaskThread$WrappingRunnable .run(TaskThread.java:61)\n\tat java.lang.Thread.run(Thread.java:750)\n" , "class" : "o.e.u.service.aop.ExceptionHandleAspect" , "container_id" : "5e182ba34d081657a0460c113a706b3d518d80ff5aa5fa7b282a55301820b069" } }
ClickHouse为了方便统计和分析,最后具体处理日志时,会使用全新的一个topic和全空的表,确保分析过程不受干扰。
由于Batch的存在,丢失若干条是可以理解的。
表名
含义
消息数据量
入库数据量
BATCH大小
备注
default.logmanagementsystem
日志详情存储
暂未统计
236800
100
数据重跑了很多遍,但不知道为什么最后回滚代码 也嗯是写不进去ClickHouse了,重启服务器和IDE也没用 ,咨询助教也没能获得帮助,所以上面没有记录了。
也许重新配一次环境可以解决?怀疑是环境出问题了,因为代码已经回滚了。
最后发现数据库可能似乎确实有点问题。但更要紧的问题是,在之前的filter中没有考虑到空值的情况,一两条异常把插入过程卡住了。这个异常在本地没有显示出来,但是在放上集群跑的时候出来了。
数据库相关语句如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 drop table logManagementSystem;truncate table logManagementSystem;create table logManagementSystem( timestamp Int64, date Nullable(DateTime('Asia/Shanghai' )), level Nullable(Enum8('TRACE' = 1 , 'DEBUG' = 2 , 'INFO' = 3 , 'WARN' = 4 , 'ERROR' = 5 )), appName Nullable(String), thread Nullable(String), class Nullable(String), line Nullable(Int32), msg Nullable(String), stack_trace Nullable(String), log Nullable(String), container_id Nullable(String), container_name Nullable(String), source Nullable(String), uuid String ) engine = MergeTree ORDER BY timestamp ; SELECT count (* ) from logManagementSystem
ClickHouse的Log引擎不支持删除记录,只能整个表清空。换成 MergeTree 引擎可以解决,但录入效率就没那么高了。我们的可视化板块中不提供相关功能。
可视化说明 前端 可视化前端使用 Vue + elementUI开发,绘图库使用了eCharts。可视化前端分为四个部分。
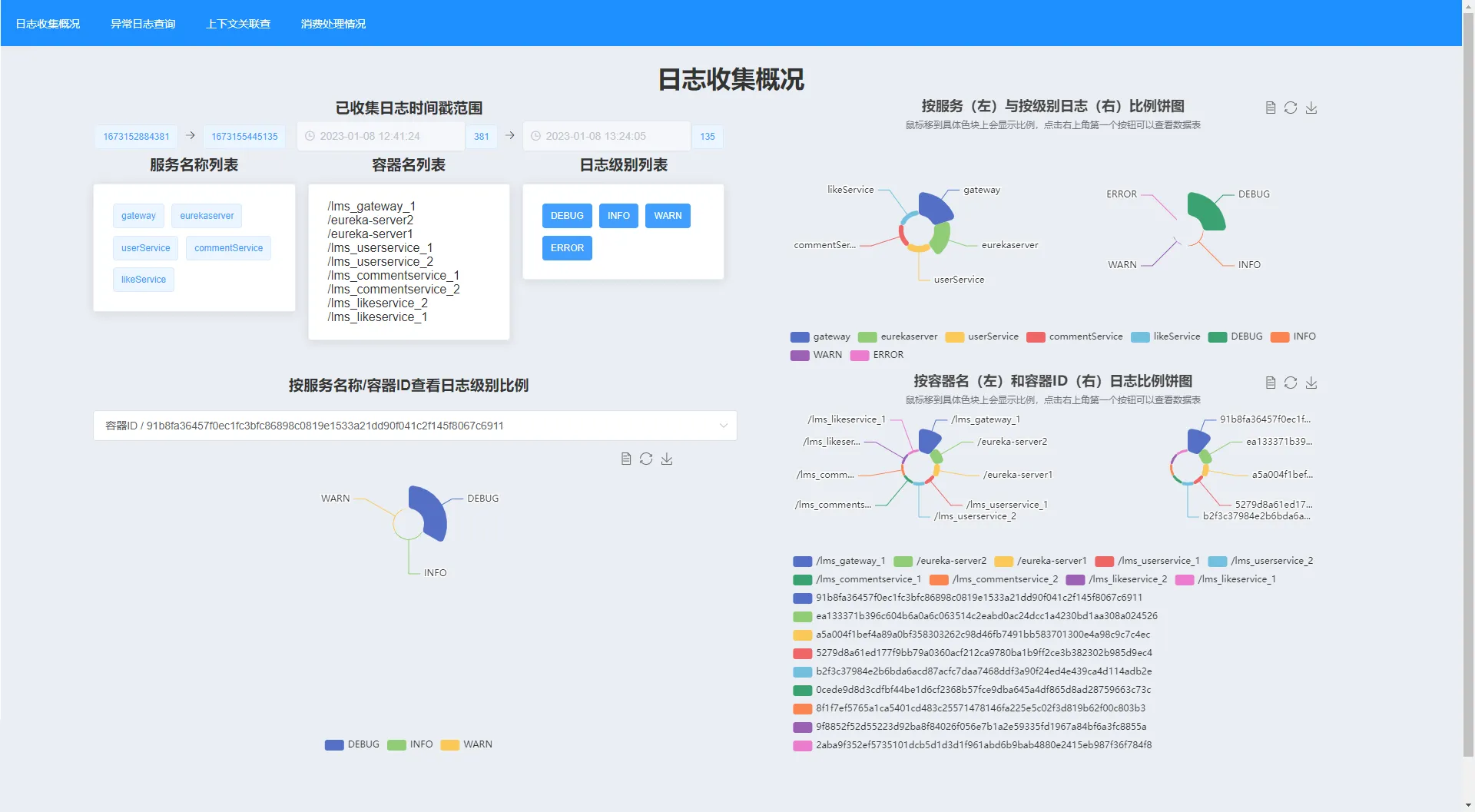
日志收集概况
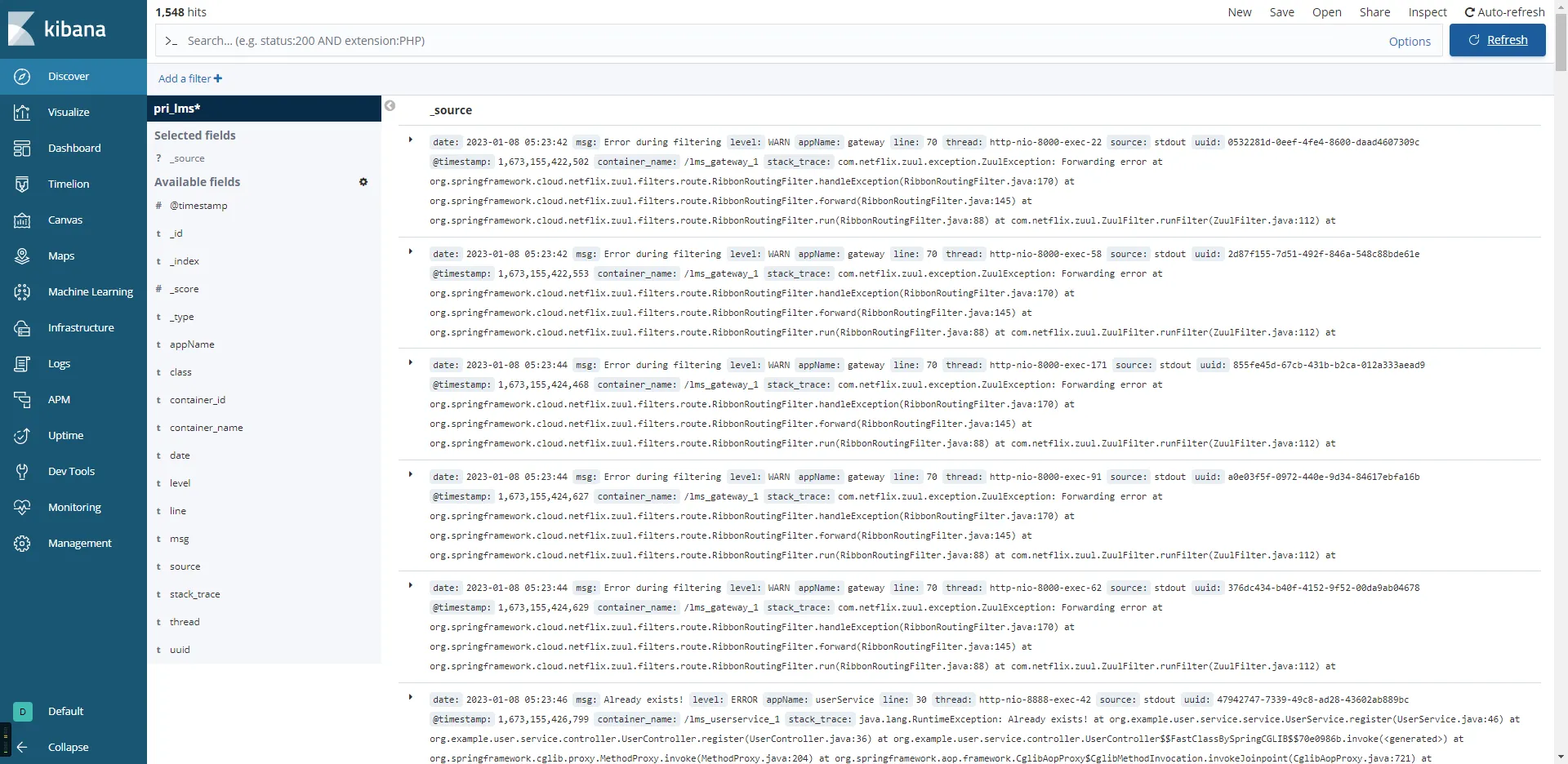
在这个页面用户可以查询到数据库已收集到的日志的总体情况,如时间范围、服务名称、容器名列表等基本信息和数量分布、级别分布等统计信息。并可以根据容器ID或者服务名称查看具体的日志级别比例情况。
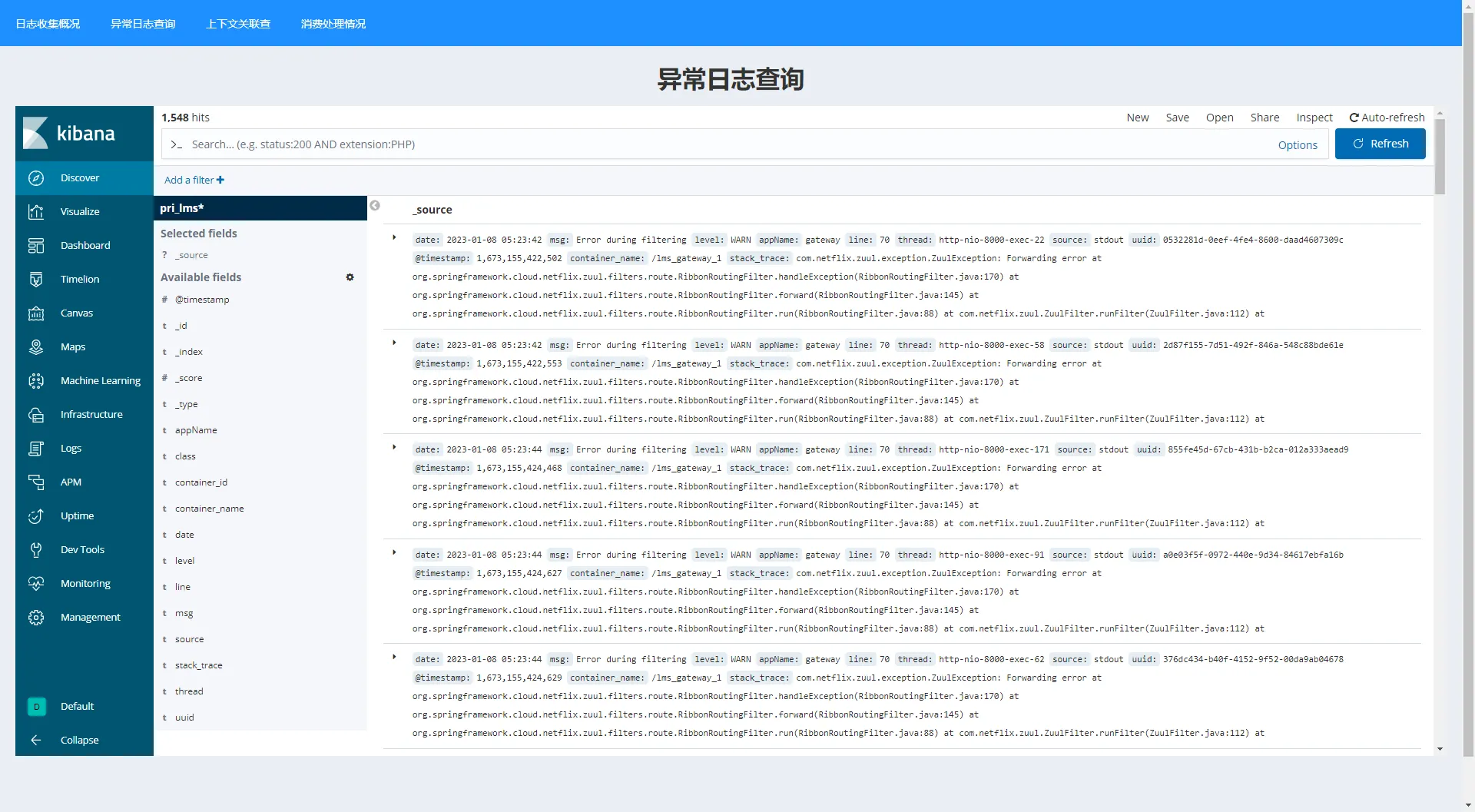
异常日志查询
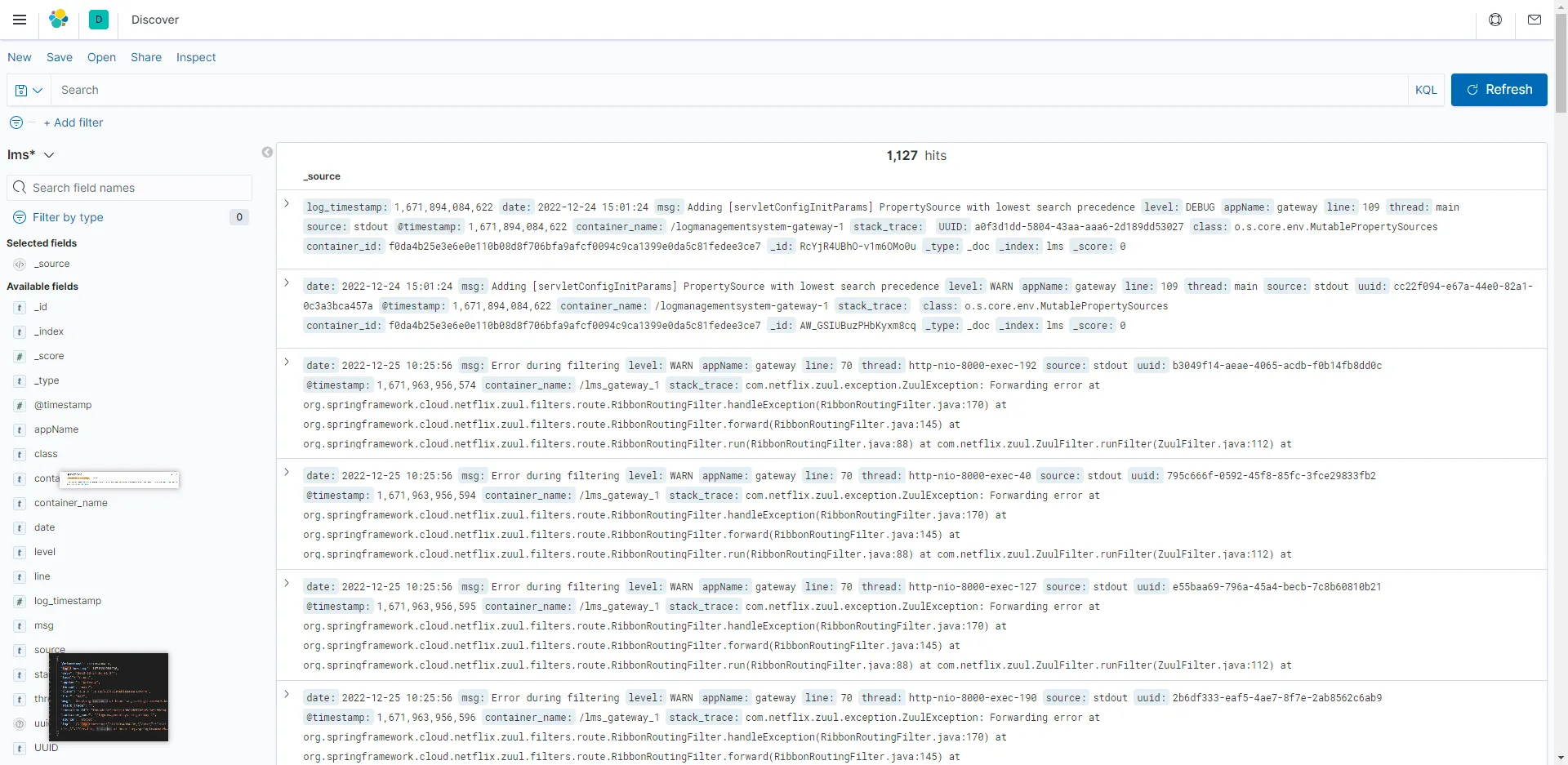
在这个页面对应的异常日志的timestamp时间戳以及对应的uuid,可以用来在下面的上下文关联查 查询该时间节点附近的日志列表,或者是直接使用uuid获得日志原文。
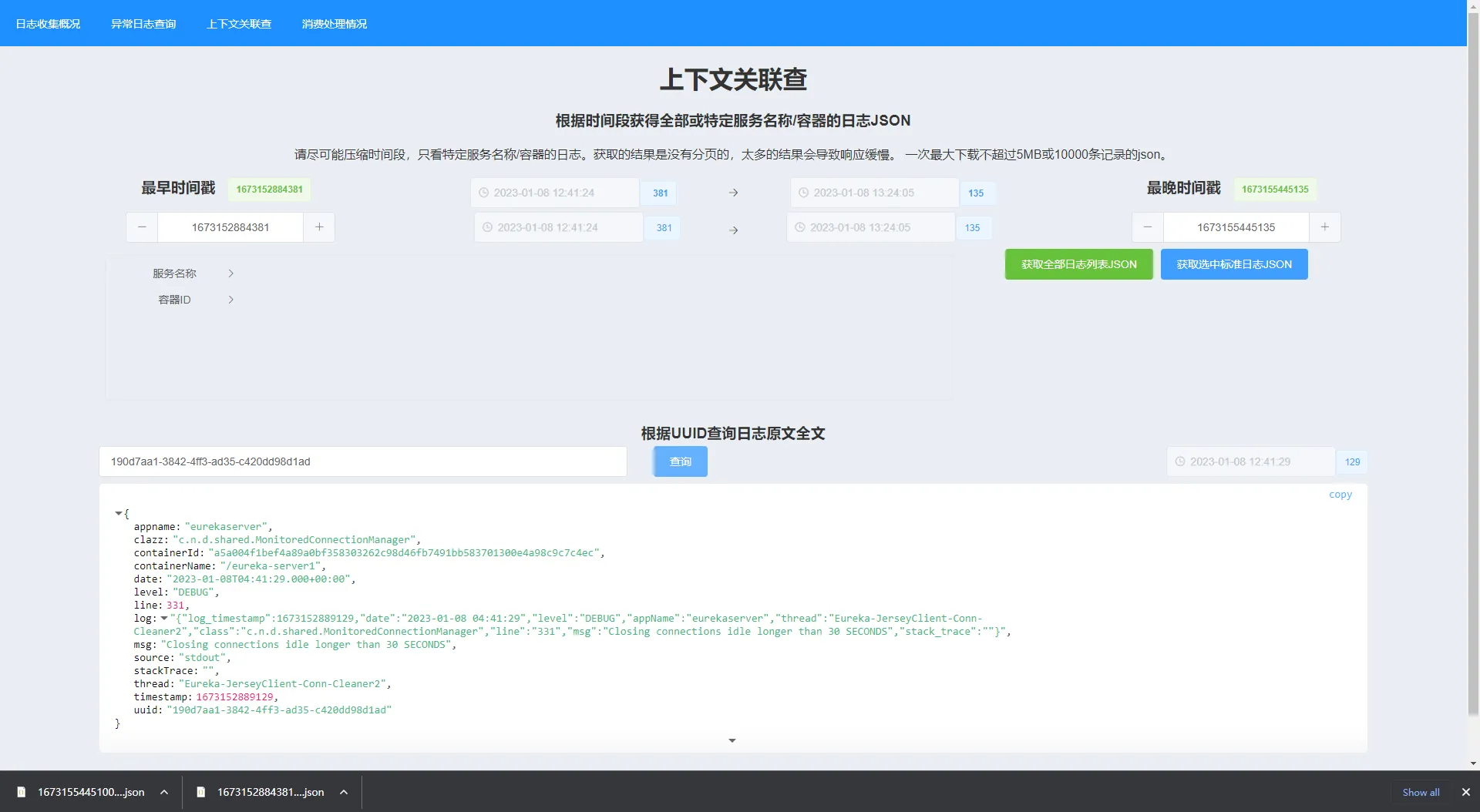
上下文关联查 在这个页面可以获取全部或者或特定服务名称/容器的日志JSON。JSON默认按时间戳降序排列,方便回溯。
也可以在这页面使用日志的UUID获得日志的全文。
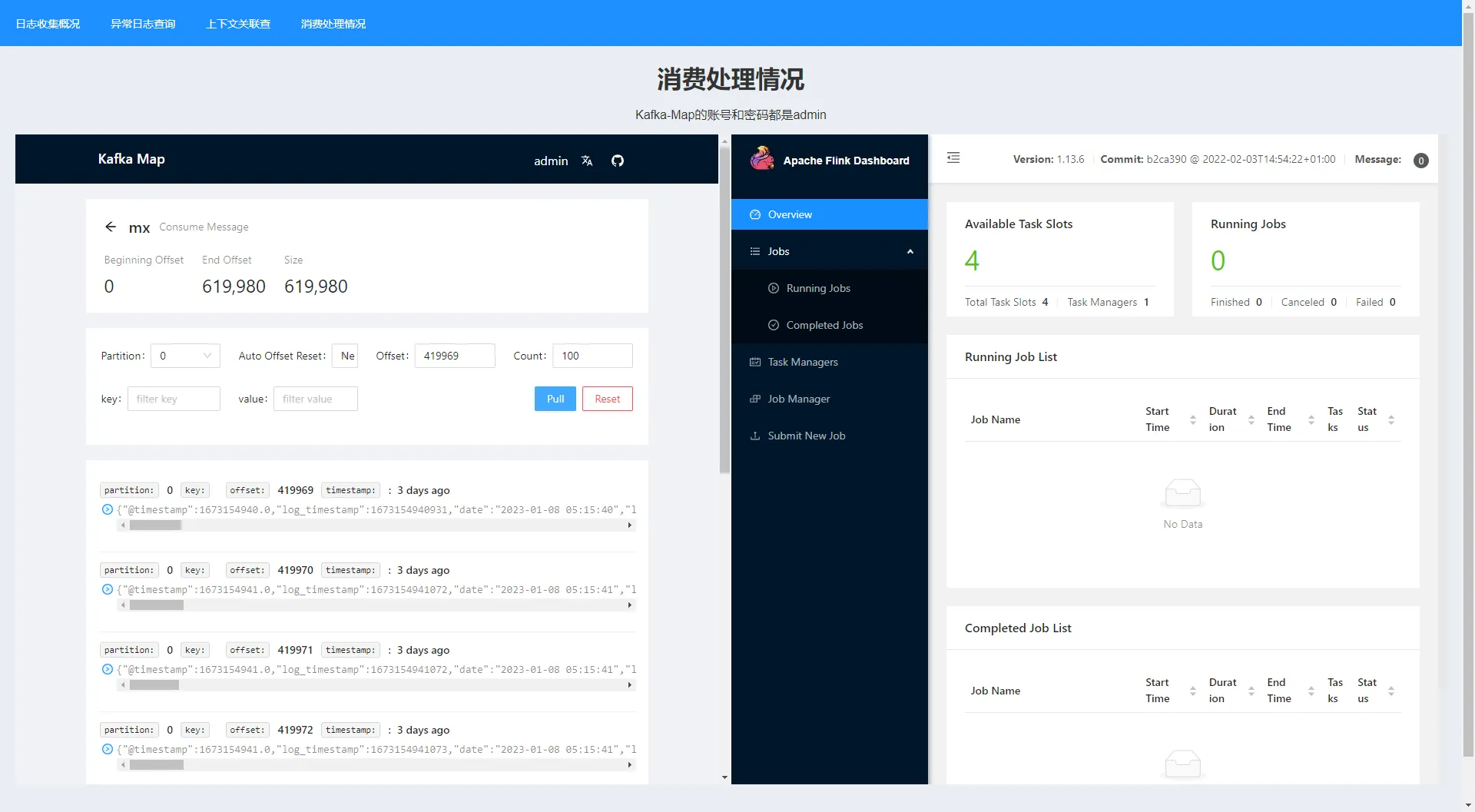
消费处理情况 该页面实际使用iframe内嵌了Kafka-Map和Flink的前端面板,可以观察到日志收集到Kafka和Flink上ETL实时处理的实际情况。
后端 可视化后端本身也是一个SpringBoot应用,通过访问ClickHouse数据库来获取相关信息。我们使用Apifox进行API管理和本地测试。该后端服务于前端的 日志收集概况和 消费处理情况两个部分。所有返回的结果都已经用 ResultVo进行封装,不过其中的msg存放的是变成字符串的data列表的长度。
功能点总结 我们使用了结合Kibana,Kafka-Map等可视化仓库的方式实现可视化展示。
Kibana可以方便地使用KQL进行日志的分析和筛选。
Kafka-Map可以看到当前消息消费的进度。
核心点 :white_check_mark: 日志源构建
编写了符合要求的微服务和对应的压测脚本,日志产生的速度符合要求。
:white_check_mark:日志收集
程序日志在容器中输出到标准输出,而后通过log driver被收集到fluentbit,最后统一发送到Kafka消息队列中,送到Flink上的ETL程序中进行处理,最后根据实际情况输入 ClickHouse和elasticsearch。
:white_check_mark:日志存储
同上。
ClickHouse的Log引擎不支持删除记录,只能整个表清空。换成 MergeTree 引擎可以解决,但录入效率就没那么高了。我们的可视化板块中不提供相关功能。
:white_check_mark:日志管理
对日志打标签:ETL可以通过解析文本或者额外添加获得额外信息,并添加到日志中,比如我们已实现的UUID添加。在微服务方面,我们的日志设计已经将尽可能多的重要信息纳入其中,如行号,类名,线程等,确保可以从日志中溯源问题。
按标签搜索日志:Kibana页面可以用GUI或者KQL查询。也可以直接编程访问 ClickHouse 或者是elasticsearch。
可视化 :white_check_mark: 要求可查看日志收集进度,堆积情况
可以在Kafka-map中查看日志消费情况。
:heavy_minus_sign: 要求可在线执行对日志创建标签
fluentbit会把传来的Json格式的Json解析后把项目添加到消息中,原始消息内容也会被保留。因此要增加新的标签,只需要改变微服务端传入的日志Json结构即可。
然而,到了ClickHouse这边,表的结构显然是不能乱改的,因此改动的标签只能体现在ClickHouse内log表项原文里面。如果硬要实现对这些标签的管理,可能需要使用虚拟列或者单独增加一个用于更改和标记tag的列。
elasticsearch方面则没有这些顾虑,因为它能自动解析Json得到对应的标签。
:white_check_mark: 要求可按标签搜索日志
Kibana页面可以用GUI或者KQL查询。
:white_check_mark: 要求可查看具体日志内容
可以用Kafka-map来看消息里的日志原文。


单纯只写入
上面50万条消息是在保持压测的状态下,在7分钟内产生的。其中产生的

(设置为固定值,都还是卡在某些消息上)总是在循环插入或者循环遍历卡在某几条消息处,原因不明。之前跑的还好的数据库结果也清掉了,数据无法保持一致,干脆放弃。