2022春数据集成环境搭建
~
承载平台
承载平台是YDJSIR的安装着Windows10 教育版的台式机上的HyperV虚拟机。该虚拟机利用虚拟交换机桥接到路由器上,而后连到南大校内网。
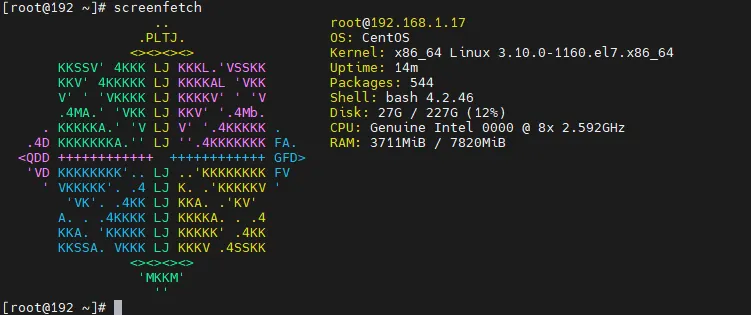
性能方面,分配了QQBZ(i9 9900 ES版,以7核心超线程状态运行)的四个物理核心,宿主机内存双通道32GB,8GB静态全量分配给虚拟机。
为了方便团队协作,YDJSIR在路由器(网件R8000P)上部署了特定工具。队友可以通过特定工具的方式连到YDJSIR的宿舍内网,访问上述虚拟机和YDJSIR的NAS和软路由等服务。
所有对服务器的访问均通过SSH进行,该虚拟机不直接映射任何端口到校内网。
环境一览
软件版本
1 | . |
全部启动后jps查看如下。
1 | [root@192 bin]# jps |
ConsoleConsumer和ConsoleProducer在实际使用时倒不一定要启动。
StarRocks最终没有被选用,除它以外其他的服务都会开机自启。
端口占用
由于这些应用有时候会随机选择一些高位端口,下面只列出相对固定的端口。
| 类别 | 用途 | 端口 | 是否可以网页查看 | 是否为默认端口 |
|---|---|---|---|---|
| SSH | SSH | 22 |
否 | 是 |
| MySQL | 数据库 | 3306 |
否 | 是 |
| aapanel | 运维面板 | 7800 |
是 | 是 |
| Spark | 主页端口 | 8080 |
是 | 是 |
| Worker1端口 | 8081 |
是 | 是 | |
| submit时worker端口 | 4040 |
是 | 是 | |
| 接受任务端口 | 7077 |
否 | 是 | |
| Hadoop | Namenode | 50070 |
是 | 是 |
| SecondaryNamenode | 50090 |
是 | 是 | |
| HDFS | 9000 |
否 | 是 | |
| yarn.resourcemanager.webapp.address | 8099 |
是 | 否 | |
| yarn.resourcemanager.scheduler.address | 8076 |
否 | 否 | |
| StarRocks | fe网页面板 | 8030 |
是 | 是 |
| be网页面板 | 8040 |
是 | 是 | |
| be_heart_port | 9050 |
否 | 是 | |
| be_port | 9060 |
否 | 是 | |
| MySQL-Connecter | 9030 |
否 | 是 | |
| Flink | 网页面板 | 8088 |
是 | 是 |
| Kafka | broker | 9092 |
否 | 是 |
| zookeeper | 2333 |
否 | 否 | |
| ClickHouse | http_port | 8123 |
是 | 是 |
| tcp_port | 9001 |
否 | 否 | |
| mysql_port | 9004 |
否 | 是 | |
| postgresql_port | 9005 |
否 | 是 |
环境变量
/etc/profile
1 | JAVA_HOME=/usr/local/java1.8 |
配置文件
由于配置文件过多,仅和配置Java环境变量和端口相关的此处从略,仅列出重要项。
Hadoop
$HADOOP_HOME/etc/hadoop/core-site.xml
1 | <configuration> |
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
1 | <configuration> |
$HADOOP_HOME/etc/hadoop/mapred-site.xml
1 | <configuration> |
$HADOOP_HOME/etc/hadoop/yarn-site.xml
1 | <configuration> |
搭建过程与参考链接
虚拟化、系统安装和SSH配置
情况已在承载平台中描述,此处略。
配置环境变量
如前文所述。修改完后要执行如下命令。
1 | source /etc/profile |
aapanel面板搭建
从官网获取脚本,直接安装即可。数据库部分,首次加载面板时选择快速一键安装MySQL。用aapanel打开了系统所有端口。装好后显然该服务是默认启动的。
Spark和Hadoop搭建
先搭JDK1.8,而后是Hadoop(修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh配置JDK路径为/usr/local/java1.8,和上面提到的那四个xml文件,创建好HDFS对应的文件夹——体现在XML中并执行HDFS初始化hadoop namenode -format ),最后是Spark(修改$SPARK_HOME/conf/spark-env.sh,添加JDK路径和Hadoop路径相关信息)。
1 | # $HADOOP_HOME/etc/hadoop/hadoop-env.sh |
1 | # $SPARK_HOME/conf/spark-env.sh |
主要参考了如下链接。
https://ydjsir.com.cn/2021/10/17/initSpark/ (YDJSIR在《云计算》课上搭Spark的心得)
https://blog.csdn.net/isoleo/article/details/78394777
https://blog.csdn.net/walkcode/article/details/104208855
Hadoop部分参考了如下链接以防止与StarRocks端口冲突。具体配置详情查看上面的配置文件。
https://blog.csdn.net/Yuan_CSDF/article/details/122116270
设置开机启动的过程在后面。
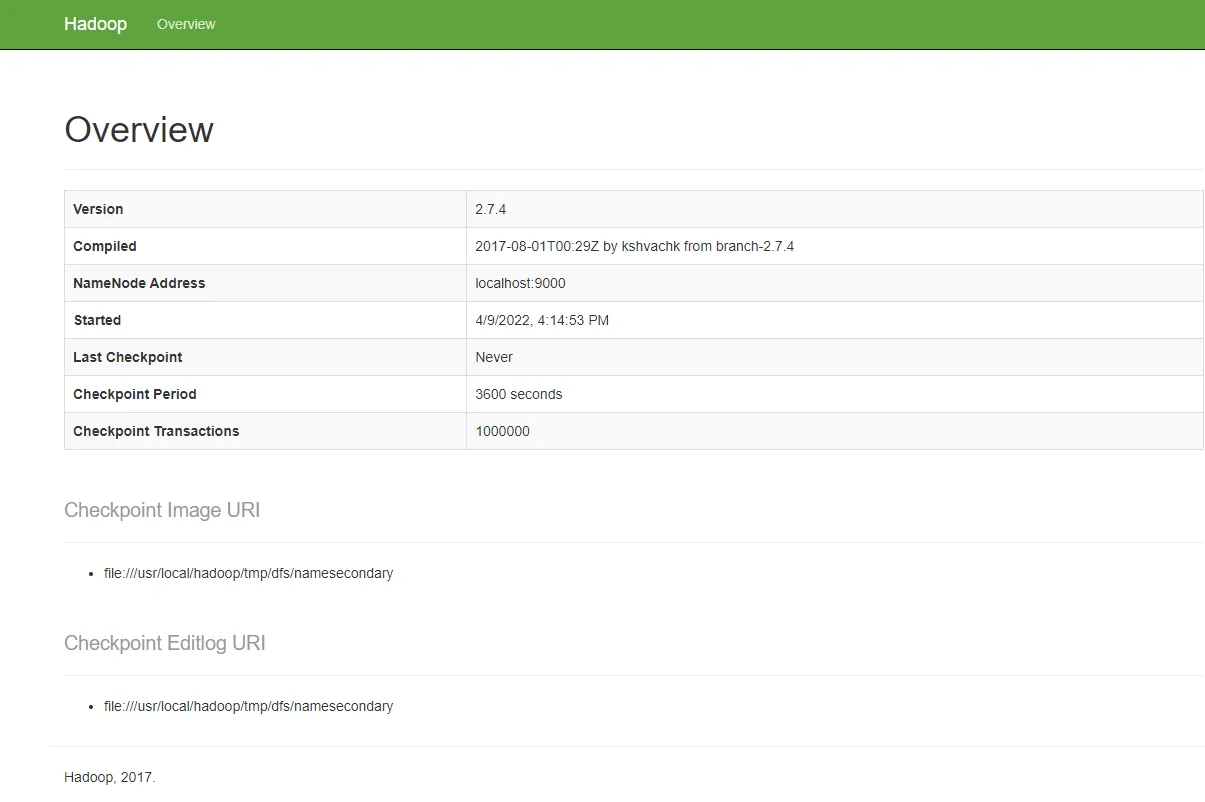
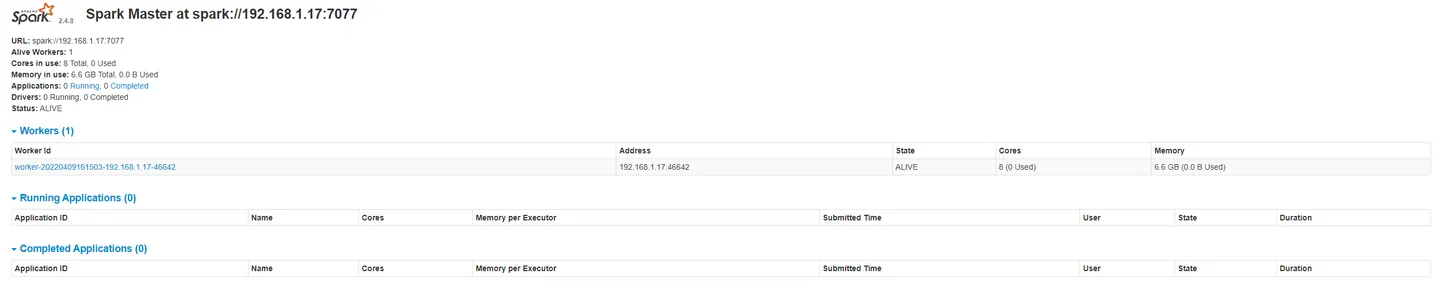
Scala搭建
直接装官网下载的rpm包。rpm装完即可。

StarRocks搭建
完全按照官网文档进行。
https://docs.starrocks.com/zh-cn/main/quick_start/Deploy
该服务没有设置开机自启,因为后面没有用到。
ClickHouse搭建
完全按照官网文档进行。
1 | sudo yum install -y yum-utils |
为了防止与Hadoop的HDFS进行冲突,修改了tcp_port为9001,并允许所有网络访问(否则只能本机)。
1 | <tcp_port>9001</tcp_port> |
设置开机启动的过程在后面。
Flink搭建
完全按照如下链接进行。
https://www.jianshu.com/p/bbaa8d72cfcf
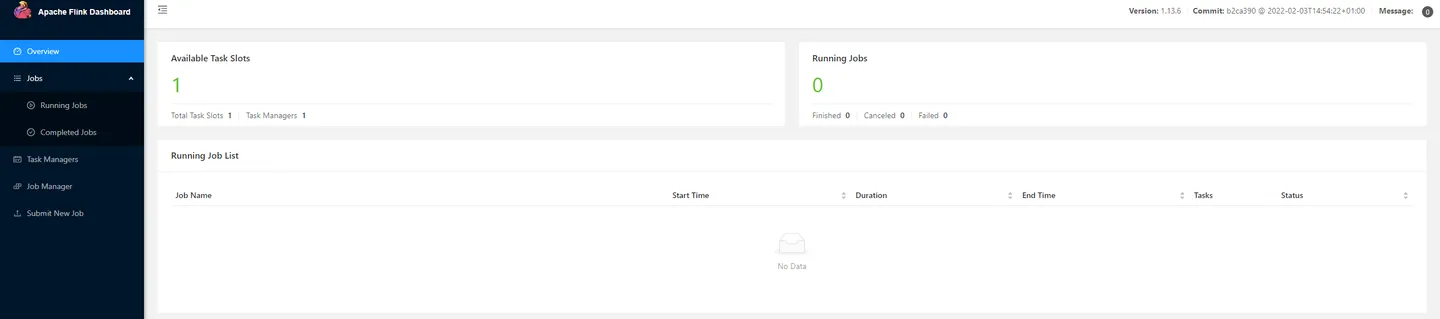
设置开机启动的过程在后面。
Kafka生产端搭建
完全按照如下链接进行。
https://www.cnblogs.com/qpf1/p/9161742.html
参考如下链接修改了配置。
都改为192.168.1.17的IP。且ZooKeeper监听的端口修改为2333。
Kafka没有设置开机自启,启动过程如下。
1 | nohup $KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties > zookeeper-run.log 2>&1 & # 启动ZooKeeper |
设置服务开机自启
修改/etc/rc.d/rc.local,而后对该文件chmod +x /etc/rc.d/rc.local 。
1 | /opt/shell/startSparkAndHadoop.sh |
/opt/shell/startSparkAndHadoop.sh
1 | /usr/local/hadoop/sbin/start-all.sh |
设置ClickHouse服务自启。
1 | systemctl enable clickhouse-server |